Python¶
Lec1 & 2¶
All data are stored as binary(二进制)
Bit or Byte
1 bit = 0/1
1 byte = 8bits
- Expressions and Statement 表达式和语句
4/2import math - Operators 运算符号
+=*/ - Variables 变量
x=5中的x - literal 字符
x=5中的5 - comment 标注
#balabala - keyword 关键字 (35个)
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
类型¶
type() 反馈变量或字符的类型
- int
- float
- str
- complex
注意!0+1j中,0和1均为float型
对于 complex 型的 c=4+2j,c.real为实部,c.imag为虚部
complex()用法
complex(real=2, imag=3) >>>(2+3j)
complex(3,4) >>>(3+4j)
complex(10) >>>10+0j
complex("4.1+3.9j") >>>(4.1+3.9j)
括号中不能有空格,否则为error无法转化
j表示数学中的复数 i,大小写注意!
占位符¶
x = 65
print("%f" %x)
>>>65.000000 默认六位小数
print("%.2f" %x)
>>>65.00
print("%c" %x) x为ASCⅡ码,返回对应的值
>>>A
print("%s" %x) or "%d" or "%i"
>>>65
print("The skyscrapter %s has a height of %f m" %(building,height))
#可以连续使用多个占位符,用括号
b = '2025-%s' %"New Start"
print(b)
>>>2025-New Start
#已经是字符串了,不用转换,但是起到占位符用法,没有一点问题!!!
!!! info "1.返回的均为str格式!因为print只输出str格式,但是print括号内的可以是float和int"
but:
1. `%s`:用于格式化字符串(string)。它可以接受任何类型的对象,并自动调用对象的`str()`方法来获取字符串表示。如果传入的不是字符串,它会尝试将其转换为字符串。
2. `%d`和`%i`:这两个都用于格式化整数(integer)。在大多数情况下,它们可以互换使用。它们要求传入的对象必须是整数,或者可以被转换为整数(例如,浮点数会被**截断**为整数)。如果传入的对象不能转换为整数,则会抛出异常。
2.关于 print()的逗号在输出时自动转化为空格,a可以不是str
str.title() 把文本中的每一个词首字母大写
str.upper() 把文本中的所有字大写
str.lower() 把文本中的所有字小写
关于math库中的 log()¶
from math import log or import math math.log
log的默认底数为e, 更完整的是log(x,base)即底数在后
Lec3 - if and loops(for & while)¶
a是str, 不能直接和数字比较,要int()
Lec4 - list¶
let x = [1,2,3,4]
del x[1] 删除索引为1的元素,后面补上
x.sort() 把列表x升序排序
关于.sort() 和 sorted()
.sort()
升序排序后返回None,但x自身已经排序完成
也就是 x = x.sort() 后,x为None
.append() 和 .reverse()同理
括号中为 reverse = True 时降序排序,不填时默认为False(升序)sorted() 同理
括号内可以选取排序的参考对象,见#^6244d2中的lambda
sorted()
返回升序排序后的结果
b = sorted(a, key = lambda s: s[1], reverse = True) s为元组
可以对列表、字符串、元组、字典排序
当对字典的键值对排序时,要用.items() 获取键值对
x.index( element ) 找到x中第一个出现的element的索引
关于index和find
均只能找到的第一个所求str[的首字符]出现的索引
index可用于str和list;但是find只能用于str
但是index找不到时直接报错返回error;find找不到时返回-1
enumerate(x[,start=0]) 返回以(索引,值)为单个元素(tuple元组)的列表 start默认为零
它返回的是一个枚举对象,无法直接被print;但可以通过list()转换或loops来获取元组
zip()同理无法直接被print #^2f6664
replace(str1,str2) 把str1换成str2
.strip() 默认是把str首尾的空格和 '\n' 全部删除,但当括号内有另外的str1时:
.isdigit(), .isalpha() 前的字符串,不能含有空格
.islower(), .isupper() 前的字符串,可以含有空格
.isalnum() 用于检查字符串中的字符,是否 全是 字母或数字 (字符串 有 空格则返回False)
sum(list) :list里所有元素均属于int或float或complex时,求和 否则为TypeError
Lec5 - Functions¶
错题反省
def dec(x = 2, y = 1):
return x + y
y = z = 0
y = dec(2, 2) * dec() + dec(1) * dec(y = 2.5)
print(y)
dec(2,2) 为x=2,y=2
dec() 为按照默认值x=2,y=1
dec(1) 为x=1, y用默认值1 (当只提供一个未指定的参数时,Python 会将其分配给第一个参数)
dec(y=2.5) 为x=2,y=2.5 y为指定参数赋值,x则用默认参数
函数参数赋值的其他注意点
dec里的参数为 x 和 y ,那么后面的操作中就不能出现 dec(t=1) 否则报错
lambda 和 def 的作用类似,只不过是在一行内定义函数,如:
xxx = lambda a : a+8
print(xxx(5))
>>>13
z = ['ab','bc','ca']
z.sort(key = lambda a:a[1]) #这里a为z中的元素,临时定义的变量
print(z)
>>>['ca','ab,'bc']
关于函数局部变量的问题
函数执行完毕后,其局部命名空间就会被销毁。全局作用域不会保存局部工作区的变量
这个时候如果试图从函数外部访问函数内部的变量,就会引发 NameError
Lec6 - Files¶
-
Open the file to read/write
-
方法一:
myfile = open('words.txt','r')"r"为读取;"w"为编辑(write)不写就默认是r
结尾加myfile.close() - 方法二:
with open( 'words.txt' ) as myfile:
open()accepts two values of typestras arguments and returns a value of typefile.
关于读取文件路径
如果只有文件名,则文件处在代码相同的位置
否则则需要定位:
'C://users//Edwin Jing//Desktop//words.txt'
1. 可以用 \ 替换 /
2. C盘后必须跟两个斜杠
'\n' - newline 单纯光标向下一行,列不动
'\r' - carriage return 光标回到最左侧
print(Hello\rYou) >>>Youlo
Hello已经打好了,但是输出You之前光标又回到最左侧,所以Hel被覆盖了
'\t' - tab
' ' - space
-
从内存中读取数据
mydata = myfile.read()全读并返回str 包括'\n'
mydata = myfile.readlines()以\n为分隔符,返回列表,每一行str为一个元素
元素末有'\n' -
Close the file
myfile.close()关闭的不是读取的数据,而是open的文件 -
Use the data
a = a.split(',') split()是不能对list操作的,只能对str操作
split()相当于遍历字符串找到空格,然后把空格前和空格后切开
这里ZJUI前的空格左边没有其他字符了,所以list的第一个元素就是空(``),最后一个元素同理
.join(list) 点前为要使用的连接符号(' '最常用),括号内为初始列表
把列表中的元素用连接符连接并以str形式保存
zip() 同时遍历 / 使用两个相同长度的列表
当可迭代对象长度不同时,以最短的为准(多余的被舍弃)
letters = [ 'A','B','C','D' ]
numbers = [ 1,2,3,4 ]
for letter, number in zip( letters,numbers ):
print( '%s pairs with %i' % ( letter,number ) )
zip() 和 enumerate() 一样,它返回的是一个枚举对象,无法直接被print;但可以通过list()转换或loops来获取元组
How do we read a .csv into python?¶
假设一个csv文件:
name, age, city
Alice, 30, New York
Bob, 25, Los Angeles
Charlie, 35, Chicago
Method 1:
myfile = open('cafePrice.csv')
rows = myfile.readlines()
for row in rows:
print( row.strip() )
myfile.close()
Method 2:
import csv
with open('data.csv', 'r') as file:
reader = csv.DictReader(file[, fieldnames=['name', 'age', 'city'],delimiter=',']]) # 假设文件没有标题行,我们指定列名;delimiter默认是逗号,是csv文件的分隔符
for row in reader: #reader的类型是csv.DictReader,可以用for来遍历(但只能遍历一遍);也可以用list()转换成列表以允许多次遍历
print(row)
>>> {'name': 'Alice', 'age': '30', 'city': 'New York'}
{'name': 'Bob', 'age': '25', 'city': 'Los Angeles'}
{'name': 'Charlie', 'age': '35', 'city': 'Chicago'}
reader.fieldnames # 列名列表
DictReader 的特点
- 自动使用第一行作为键
- 每行返回一个有序字典(OrderedDict),这些有序列表被容纳在一个列表里
- 通过列名而不是索引访问数据
示例¶
Lec7 - Mutability(可变性)¶
id() 返回对象内存地址,在对象生命周期内通常不变
约等于 is (比较内存地址是否相同)
除了 b = a 这种,其他的(例如 c = a[:])都叫复制,id不同
list,dictionary,ndarray 是mutable(有alias,例如b = a b就是a的别名)
x = [1,2,3]
y = x
y[0] = 6
print(x)
>>>[6,2,3] #因为x是list,是mutable,而y和x的id是一样的,因此改变y也就改变了x
--------------------------------------------
dic1 = {'1':1,'2':2}
dic2 = {}
x = list(dic1.keys())
for n in range(2):
dic2['c'] = n
dic1[x[n]] = dic2
print(dic1)
>>>{'1': {'c': 1}, '2': {'c': 1}} #而非{'1': {'c': 0}, '2': {'c': 1}}
#因为dict是mutable,所以dic1的两个键最后指向的都是dic2的id,所以dic2最终是什么就输出什么;
#只有将dic2每次循环都重置(移到循环里),才能让id变化
str,int,float,complex是immutable(无 alias(假名))
Tuple (元组)
有序且不可变
a = (1.0) 为浮点数
a = (1.0,) 为元组
Lec8 & 9 - Dictionary¶
Let dic = {'one': 1, 'two': 2}
dic.clear( ) 清空字典中的所有键值对
dic.get( _key_ ) 得到dic中特定键对应的值 (e.g. dic['Two'] => 2)
| 特定条件下的区别 | dic[ 'two' ] |
dic.get( 'key' ) |
|---|---|---|
| 键不存在时: | 抛出 KeyError |
返回 None 或默认值 |
for i in dic: 中, i 是键
dic.items() 是键值对 键值对(entry)
dic.keys() 是键
dic.values() 是值
任何immutable的类型均可成为key
mutable的类型(
list和dict和ndarray)不行
Lec10 - NumPy¶
numpy提供数组和矢量化运算 - 而list只能逐个元素进行操作
import numpy as np
data = np.loadtxt( 'inflammation.csv',delimiter=',' )
x = np.array([[1, 2, 3], [4, 5, 6]])
print(x.shape)
>>>(2, 3) #元组
Indexing
:表示全部
mysquare = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
mysquare[:,1] >>> [1 4 7]
mysquare[:][1] >>> [3 4 5] #这里的[:]由于在前面,对mysquare没有任何影响,相当于取了mysquare全部,后面跟的[1]则依旧从行开始
mysquare[1,:] >>> [3 4 5]
mysquare[1][:] >>> [3 4 5]
mysquare[ 0:2,0:2 ] >>> array([[0, 1],
[3, 4]])
NumPy Array 是 ndarray , 是mutable
Convenient Functions
np.zeros( [shape=]( 3, ) ) #生成3*1的全 0. 列数组
or np.zeros( [shape=][ 3, ] )
np.zeros([3]) >>>[0. ,0., 0.]
or np.zeros( 3 ) #这种单层括号的只能生成n*1的,np.zeros(3,2)是会报错的
#且输出的是[0. ,0., 0.]是浮点数,后面跟上dtype=int 才是[0,0,0]
np.ones( ( 4,3 ) ) #生成4*3的全1数组 # 和zeros同理
np.eye( 4 ) #生成二维4*4数组,对角线为1,其余地方为0 # 只需且只能有一层括号
np.eye(4,3) #生成二维4*3数组,从(0,0)向右下角的对角线为1,其余地方为0 #只能有一层括号
mysquare.T # 行列转换; 但不改变mysquare,可以赋值给别的变量
mysquare.tolist() #转换array为list
mysquare * mysquare # 数组元素求平方 (并非矩阵)
mysquare.dot( mysquare ) # 作为矩阵平方
x.max() 或 np.max(x) #整个矩阵的最大值
x.max(axis=0) 或 x.max(0) #每列的最大值
x.max(axis=1) 或 x.max(1) #每行的最大值
mysquare.mean(1) #按行算平均 0为按列算平均 返回的元素均为float
np.shape() 获取行列数尺寸 <--> np.size()获取元素数目
对MATLAB而言,size()获取行列数尺寸<-->numel()获取元素数目
如何理解括号内是否还要放括号来确定矩阵大小?
事实上,需要两层括号的函数往往获取多个参数,因此如果不严加括号限定,就会让逗号暴露在外,让参数的定义不明确
例如,np.zeros(shape, dtype=float, order='C', *, like=None)获取这么多参数,如果在shape处不加小/中括号,原本代表尺寸行列区分的逗号就会被用于分配参数,就会导致TypeError
关于这一点,Lec13 - Random(实际上并非随机,用函数生成的)中的 size()也是同理
关于NumPy中的.sort()和 .argsort()
mysquare.sort() #默认括号里是1(把每一行升序排序); 返回None,但是改变mysquare
mysquare.sort(0) #把每一列从上往下升序排序
a = mysquare.argsort() #相比于sort,执行后mysquare不变,而是返回索引,告诉你怎么排序
np.linspace(st,ed,num[,endpoint=Ture,retstep = False]) 把[st , ed]这个区间分为num个数,并且以一维数组 ndarray 返回
默认endpoint = Ture(ed要取);=False时不取
默认retstep = False 即不返回另外一个存储步长的变量
np.linspace(1, 10, 10) >>> array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]) 都是float
Data Type——用 .dtype 来查看
bool(regular Pythonbool)int64(regular Pythonint) 针对64位系统float64(regular Pythonfloat)complex128(regular Pythoncomplex)
x = np.array([1,1,0,1,0])
( x == 1 ).any() >>> True
( x == 1 ).all() >>> False
Lec11 - Plot¶
import matplotlib.pyplot as plt
plt.plot(x,y,color = "blue",linewidth = 1.0,linestyle = '-',label='')
or plt.plot(x,y,'b-',label = '')
x 和 y 均为列表,且元素个数要对应;元素个数不对应则报错(ValueError)
plt.xlim(a,b) 和 plt.ylim(a,b) 分别表示图标坐标轴的范围
plt.title("")plt.legend([loc='best', frameon=False])(使用了label时,接上plt.legend()才会显示)
frameon参数反映图例是否有边框,默认为Trueplt.xlabel("")plt.ylabel("")plt.xticks(np.linspace(...))显示x轴刻度,y也一样plt.imshow()显示二维数组为一张照片,按灰度值显示 <-->plt.plot()单纯显示函数图线plt.savefig("xxx.png",dpi = 72)以每英尺72像素保存图像为png格式
plotted line 指图像
| Color | String | Marker Type | String |
|---|---|---|---|
| Red | 'r' |
Solid line实线 | '-' |
| Green | 'g' |
Dashed line虚线 | '--' |
| Blue | 'b' |
Circles 大圆 | 'o' |
| Black | 'k' |
Dots 小点 | '.' |
| Magenta 洋红色 | 'm' |
Crosshatches 叉 | 'x' |
| Yellow | 'y' |
Crosses 加号 | '+' |
| Cyan 青色 | 'c' |
多条图像的绘制
plt.plot(x,y1,'b-',x,y2,'k--') 可以实现 y1 和 y2 两条曲线的绘制
Lec12 - State¶
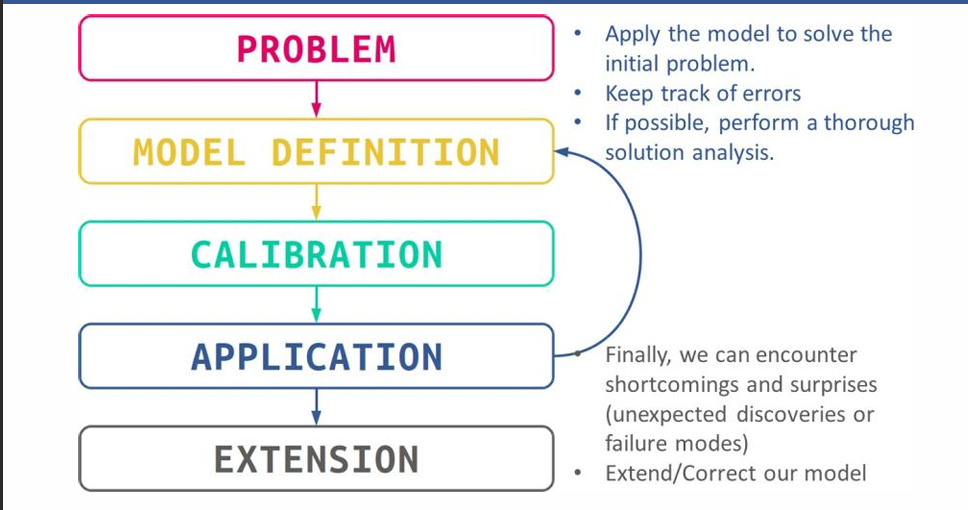
Finite Differences 有限微分¶
- PROBLEM: 明确问题和相关的约束;如果问题过大,需要被分解为可以测量的问题
- MODEL DEFINITION:包含物理和数学公式,限制条件,生成代码来实现模型
I) (First order) Forward difference, Python: v[n]= (y[n+1] – y[n]) / (t[n+1] - t[n]) 选新的那个
II) (First order) Backward difference, Python: v[n]= (y[n] – y[n-1]) / (t[n] - t[n-1]) 选老的那个
III) 用数学、物理函数建模
-
CALIBRATION:
- Verification(核实): 检查是不是解决的是所需求的问题
- Validation(验证): 检验问题是不是成功解决 在代码中就是(带入一些数据)运行一遍的意思
-
APPLICATION: 得到一些反馈
- EXTENSION:修正、完善 相比较于先前的函数模型而言
Lec13 - Random (实际上并非随机,用函数生成的)¶
均匀分步 Uniform Distribution¶
生成1000个在[0.0, 1.0) 范围内的均匀分布随机浮点数
numbers = np.random.uniform(size=(1000,)) Or np.random.rand(1000)
指定范围 [low, high)
numbers = np.random.uniform(low=1.0, high=5.0, size=(1000,))
rand不能指定范围,只能[0,1)
生成二维数组
matrix = np.random.uniform(size=(3, 4)) # 3行4列的矩阵
Or np.random.rand(3,4)
正态分布 Normal Distribution¶
numbers = np.random.normal( size=(1000,) ) 返回标准正态分布(平均值为0,标准差为1)
要模拟平均值为 10.0、标准差为 2.0 的随机分布:
离散分布 Discrete Distribution¶
numpy.random.randint([low=0,] high [, size=(,), dtype=int])
high一定要大于1,且不包含其截断小数的那个整数
但是,btw,由于python中小数点有不精确的问题,1.9999999999...也可以被视为2
size = (10,) 生成10个数; size = (2,3) 生成2行3列数组;如果为None,则只生成一个随机整数
关于 shuffle 洗牌
np.random.shuffle(list) 将一个序列(如数组)的顺序随机打乱。
注意:
shuffle会直接修改原始数组,而不是返回一个新的打乱后的数组
如果是多维数组,只会在第一维(行)上进行随机重排
关于 choice
np.random.choice(a, size=None, replace=True, p=None)
从给定的一维数组或序列中随机抽取元素。可以指定抽取的数量、元素被抽取的概率以及是否允许重复抽取
有返回,且不改变a
- a:如果是一维数组,则从中抽取元素;如果是整数,则从
np.arange(a) >>>[0,1,2,...,a-1]中抽取。 - size:输出数组的形状(默认为None,返回单个值)
- replace:布尔值,是否允许重复抽取(默认为True,即允许放回再被抽)。
- p:与a相同长度的概率数组,指定每个元素被抽取的概率(默认为等概率)。
Histograms 直方图¶
对于均匀分布,堆栈将具有相同的高度或接近高度
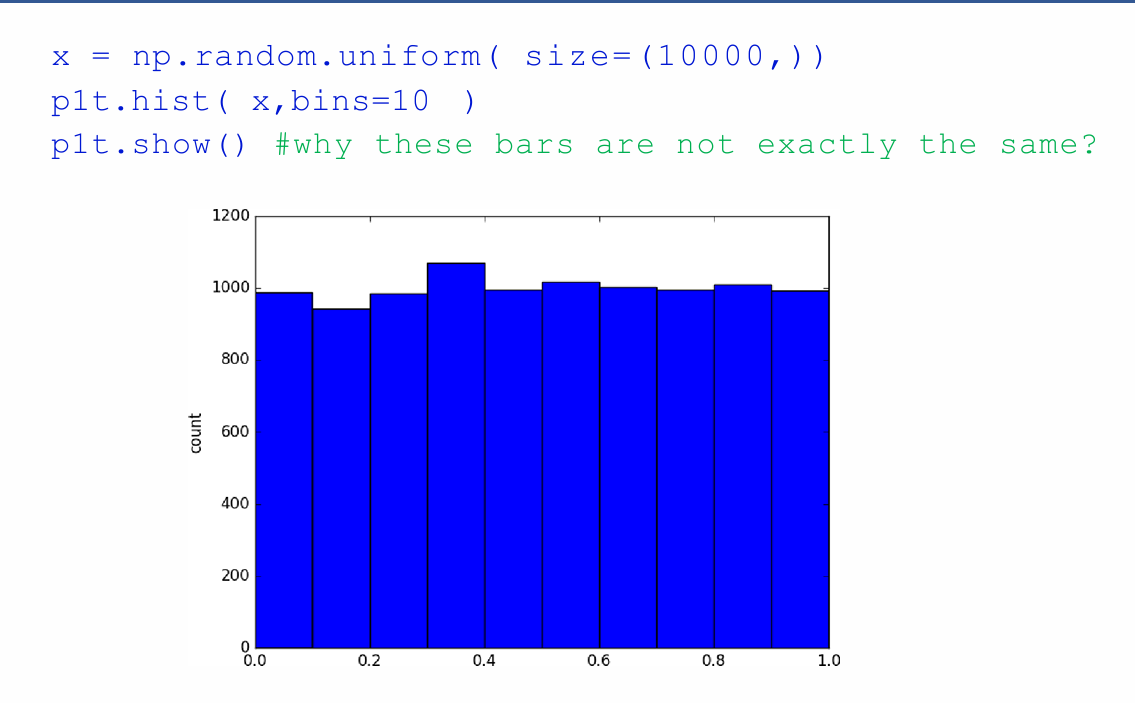
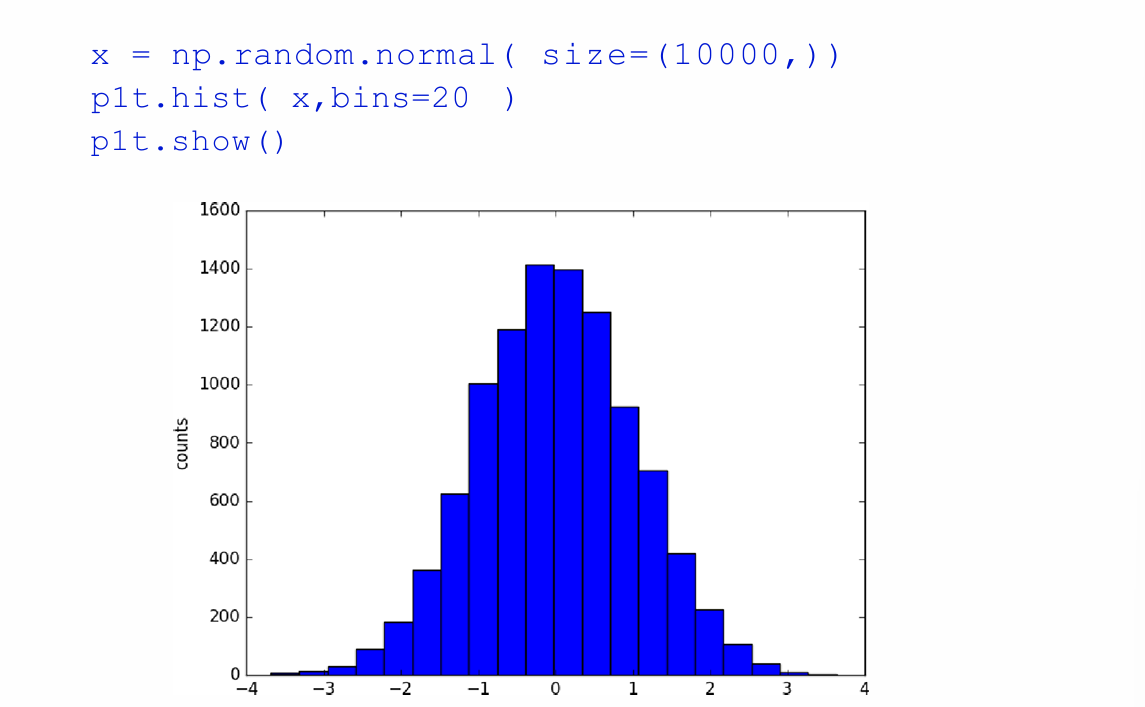
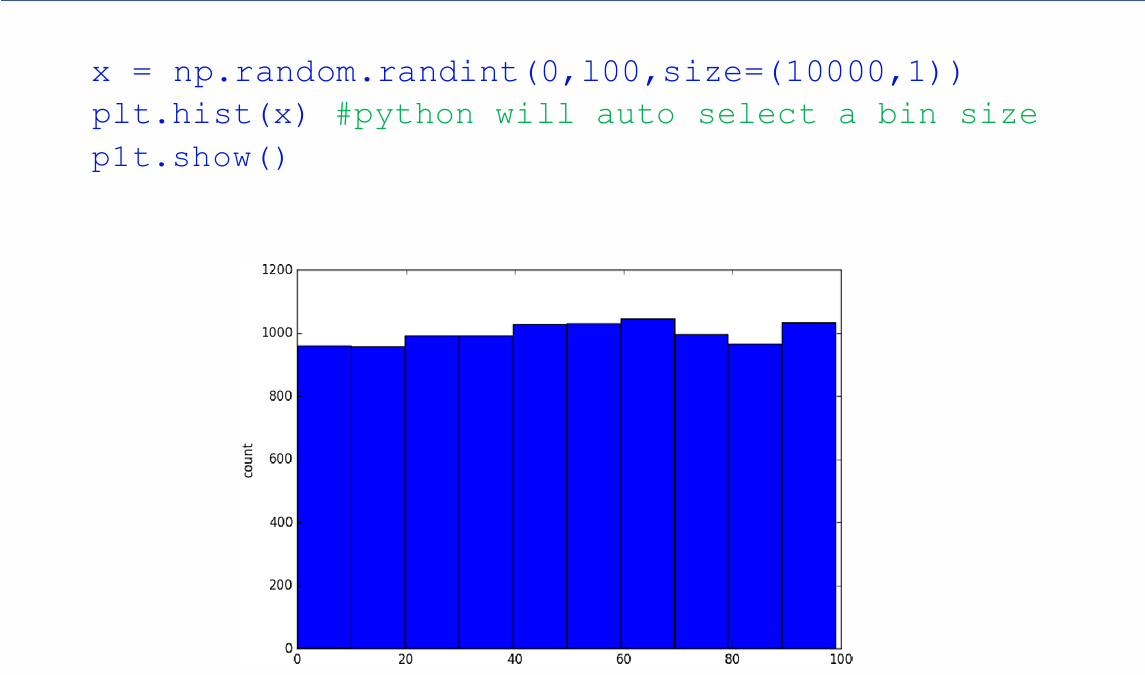
evenly distributed: 均匀分布
Lec14 - The Data Pipeline¶
Input 的三个来源:
- 用户:通过
input(). - 硬盘驱动器(电脑上的文件): 通过
openorcsv.
csv指comma-separated values(逗号分隔值):用逗号分隔不同的值,通常用于表格数据的存储和交换。 - 互联网:通过
requests[.get(url,verify = True)]. 为False(default)时绕过验证过程
要import requests
import requests
rdata = requests.get( 'https://www.github.com/' )
rdata = requests.get( 'http://samplecsvs.s3.amazonaws.com/Sacramentorealestatetransactions.csv' )
关于request.get()
rdata 类型不是str!而是 requests.models.Response(知道即可)
因此需要 rdata.text 来获取字符串
Output can be of several types:
- 文本形式, via
print. - 图标, via
pyplot(innum/plotting). - 文件, via
writeor a similar tool.
Lec15 - DEBUG¶
Bug:包括 exception、error 、逻辑错误,模棱两可或不正确的代码¶
Error(错误): 导致程序不能执行的异常(且不能在运行时被解决)¶
“Python不喜欢你的结构”
在运行前会分析词法和语法,如果token的排序不符合Python的语法规则,解析器立即停止,并且抛出Syntax errors:
- 括号不匹配
- 遗漏\错用标点符号
- 判断句中的
==打成= - 遗失冒号
-
关键字误用:
def = 535个 Keywords 被当做变量
或抛出IndentationError: -
缩进错误
- Tab和空格混用(没见过)
Exception(异常): 任何其他错误都是异常。它们是在运行过程中发现的不寻常行为,尽管不一定是意外的¶
“Python喜欢你的结构,但是没逻辑的内容让它匪夷所思”
NameError:在当前工作区(命名空间)找不到对应的变量- 拼写错误(大小写敏感)
- 在赋值前就尝试读取
- 试图在函数外部访问函数内部的变量 见#^4f0a7f
TypeError:操作或函数应用于不合适的数据类型- 数学运算的类型不兼容(字符串和int之间的加法)
- 不可调用对象(
int的切片,len(5)给整数取长度) - 不可迭代对象(
for i in 100:for需要一个序列如列表或字符串而不是一个整数为容器) ValueError:操作或函数接收到了类型正确 但内容不合适 的参数- 类型/进制转换失败(
int("Hello World")可以接受字符串类型的转换,但内容不被接受) - 数学领域违规(
math.sqrt(-1) #要cmath才行) .index()找不到- 解包时数量不匹配
a, b = [1, 2, 3] - 无中生有
open(filename,'k')只有r,w,a而没有k IndexError:索引超出序列范围KeyError:字典中没有对应的键值对时
用dict.get()方法避免报错,就像用find()来避免index()找不到会报错一样ZeroDivisionError:除以0FileNotFoundError:检查文件是否存在AssertionError:出现在assert后的条件不满足时
try:
#the main code
#if an error occurs, it goes into "except:"
except (errortype1):
#an error occurs, usually print something
except (errortype2):
#print other things
...
else:
#if no error, then run this
finally:
#Whether error or not, run this finally
浮点数的比较¶
由于大部分浮点数的二进制存储是无限循环,因此会出现精度问题
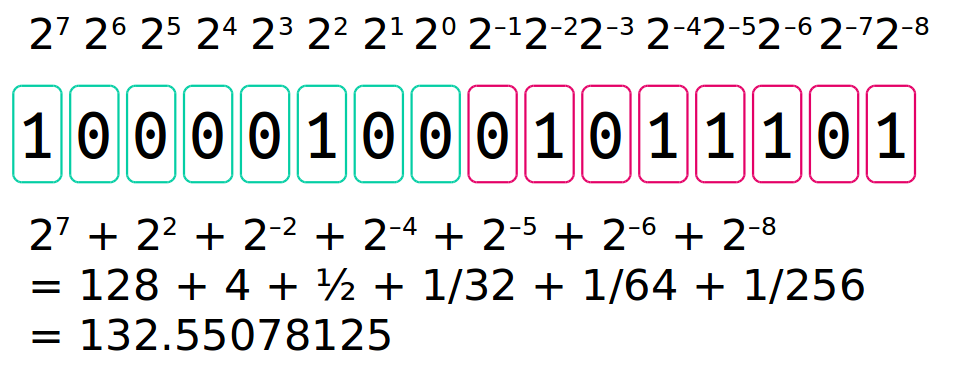
二进制0舍1入
np.isclose( a, b, rtol=1e-05, atol=1e-08)
#逐个比较a和b中的对应元素,返回一个等元素个数的列表,包含True和False
np.allclose(a, b, rtol=1e-05, atol=1e-08)
#逐个比较a和b中的对应元素,找到一个不接近的,就返回False,否则返回True(只返回一个)
Lec16 - Equations¶
%timeit -n 10 f(x) 可以比较函数运算的快慢 要先 import timeit
- 在每个计时循环中,连续执行
f(x)10次 - 测量这10次执行的总时间
- 计算平均每次执行时间 = 总时间 / 10
- 报告最快循环的平均时间
x很大时,递归函数比表达式函数慢
import scipy.optimize
> xstar = scipy.optimize.fmin( f, x0 )
#从x0开始寻找最小值,往下找,当前后两次fun差别很小的时候停止
#所以说当x0一开始在极大值点附近的时候,如果差别已经很小了,就会停在x0
> xstar = scipy.optimize.minimize( f, x0 )
#两个函数都返回一个包含多个属性的对象xstar
print(xstar.x) #返回最小值点
print(xstar.fun) #返回对应的最小值
找最大值,则给原函数取负号即可,没有相关的fmax之类的函数
Solving Equations¶
Methods:
A. Plot LHS == RHS 用图像评估零点大致位置
B. Newton’s method or variant
C. Use scipy.optimize
...
Newton's Method¶
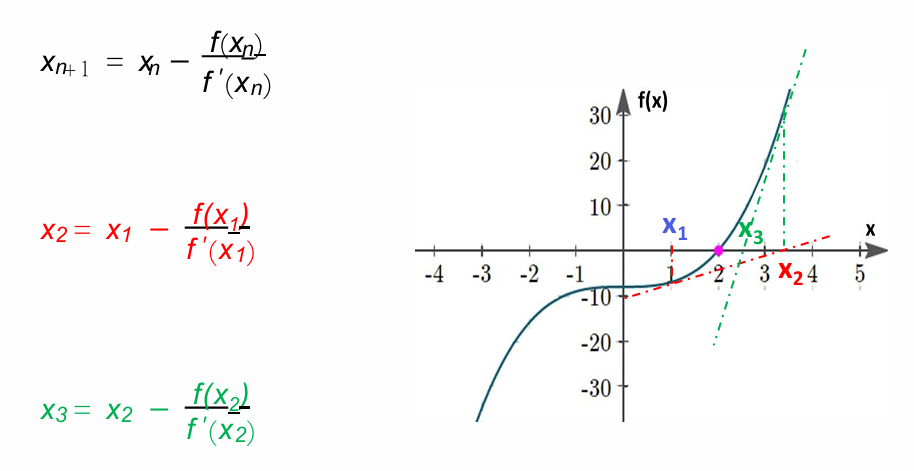
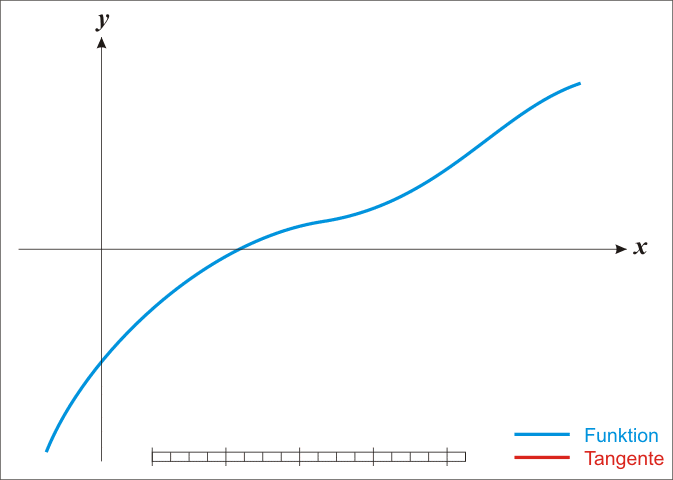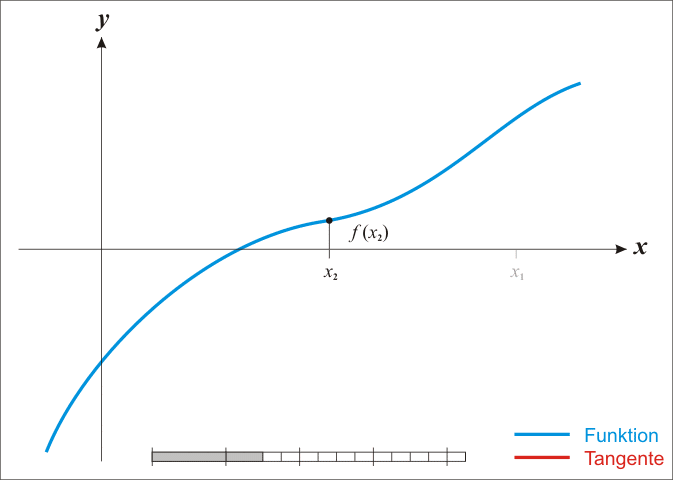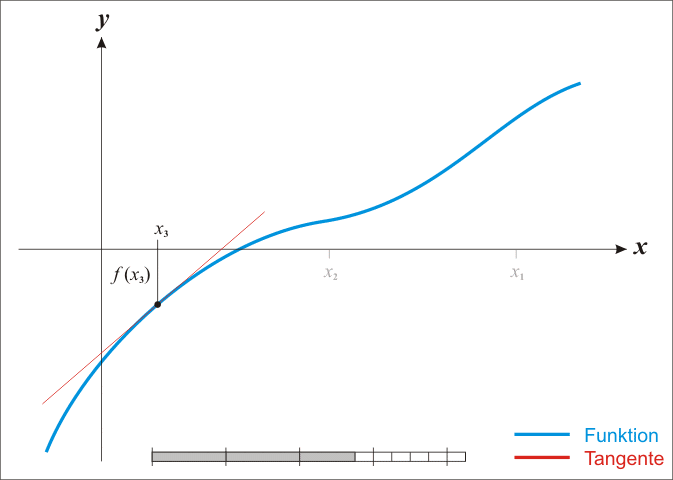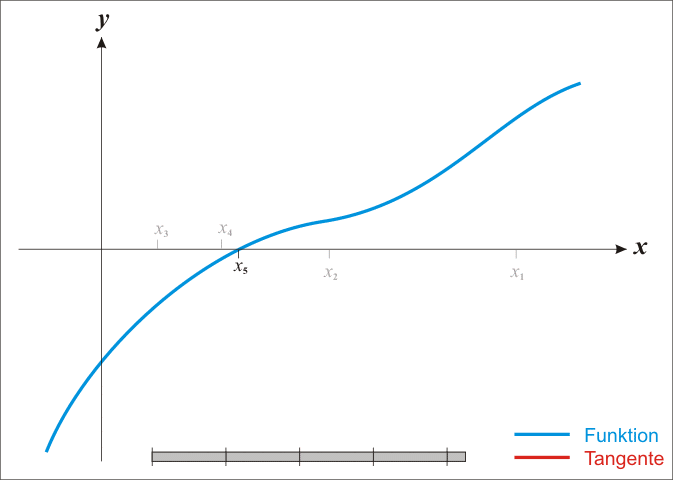
import math
def dfdx(f, x, h=1e-3):
return (f(x+h) - f(x)) / h
def newton(f, x0, tol=1e-6): # 减小容差以提高精度
d = abs(0 - f(x0))
while d > tol:
x0 = x0 - f(x0) / dfdx(f, x0)
d = abs(0 - f(x0))
return (x0, f(x0))
def f(x):
return math.cos(x) + 2 + x**3 - 3*x
# 测试不同的初始值来找到两个根
root1, fx1 = newton(f, 1.0) # 初始猜测1.0
root2, fx2 = newton(f, -1.5) # 初始猜测-1.5
Lec17 - Py-Optimize: brute¶
当我们想对群的每个子集进行分析时,使用组合。例如,要获得集合中的每一对:
from itertools import combinations #不考虑顺序,C42种
for pair in combinations( 'ABCD',2 ):
print( pair )
#以元组形式输出
from itertools import combinations_with_replacements #允许重复输出,不考虑顺序
from itertools import permutations #不允许重复输出,顺序有关,A42种
for triplet in permutations( 'ABCD',2 ):
print( triplet )
from itertools import product #允许重复输出,顺序有关
for a,b in product( 'abc','ABC' ):
print( a,b )
#相当于:
for a in 'abc':
for b in 'ABC':
print( a,b )
itertools.product(list,repeat=n)
#n个list,每个list随机抽一个,得到m*n个元组,每个元组n个元素
product 对列表就是列表中的元素,对字符串就是字符串中的单个符号来遍历
Lec18 - Optimize (找到可接受的解决方案(尽管不保证全局最优))¶
hill-climbing strategy 爬山算法(Greedy Algorithm 贪心算法)
- Set up a figure of merit
f. (价值标准) - Select a starting guess
x0(,y0,z0, etc.). - Change a feature of the guess (that is, push it in a certain direction).
- If this improves the solution, then keep it and cycle back to step 3.
- If no further improvement is possible, 结束模拟.
几类算法的特性
- Brute-force search(暴力搜索/穷举法):检查定义域内的每一个可能解,计算量大
- Hill climbing(爬山算法):这是一种迭代算法,从一个随机点开始,每次向邻近的、能让结果更好的方向移动一步;它依赖于邻域搜索,而不是从全局随机采样的子集中直接选最好的
- 随机搜索(Random Search):搜索空间(Domain)中随机地选取多个点,计算它们的目标函数值,然后从中选出表现最好的一个作为结果
”stochastically sampled subset"(随机采样的子集)“
Lec19 - Sympy-Algebra¶
import sympy or import sympy as sy
#1
x = sympy.S( '2 * x + 3' ) #不是同一个x
3*x
>>> 6 * x + 9
#2
a = sympy.S( 'a' )
b = sympy.S( 'b' )
c = sympy.S( 'c' )
x = sympy.S( 'x' ) # a,b,c,x = sympy.S('a,b,c,x')也可
eqn = a * x ** 2 + b * x + c
y = sympy.solve( a*x**2+b*x+c,x )
>>>y = [(-b + sqrt(-4*a*c + b**2))/(2*a), -(b + sqrt(-4*a*c + b**2))/(2*a)]
y[0].subs(a,1).subs(b,2).subs(c,1)
>>>-1
#3
sy.sqrt(8)
>>>2√2
sy.init_printing() 先运行,就会生成数学符号了

sympy.I is sqrt(-1) is j in python’s complex number
sympy.re(z) 复数z的实部
sympy.im(z) 复数z的虚部
sympy.pi
sympy.E is exp(1) = 2.718281828459...
sympy.exp, sympy.log, sympy.sin and others
sympy.sqrt and others
可以解多元方程组
import sympy as sy
x, y = sy.S( ’x, y’ )
eq1 = x + y - 6
eq2 = - y + x + 4
z = sy.solve((eq1,eq2), (x, y))
>>>z = {x: 1, y: 5}
五次方程开始就解不出来了
sympy.expand((x+1)*(x-1)) 展开多项式
y = x**2+4*x+4
sy.factor(y) #因式分解
>>>(x+2)^2 #数学表达式
symsy.simplify((x**3 + x**2 - x - 1)/ (x**2 + 2*x + 1))
>>>x-1
SymPy 会自动保留简单的有理表达式
sympy 默认不会合并有理表达式和多项式 b/c+x/a保持不变
sympy.together( b/c+x/a )
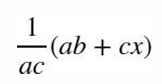
math 和 sympy不能一起用
sympy.plotting.plot( x**2 [,(x,-2,2)])
sympy.plotting.plot3d( sympy.cos( x ) *sympy.sin( y ) )
plot3d_parametric_surface(x,y,z) 曲面
plot3d_parametric_line(x,y,z) 曲线
Lec20 - Sympy-Calculus¶
微分¶
import sympy
sympy.init_printing()
x,y = sympy.S( 'x,y' )
sympy.diff( x**y,y )
>>>log(x)⋅x^y
sympy.diff( x**y,x,2 ) #求二阶导
积分¶
import sympy
sympy.init_printing()
x = sympy.S( 'x' )
sympy.integrate( sympy.cos(x),(x,0,sympy.pi/2) ) #定积分在函数后有范围
^ 这个括号很重要
>>>1
multiple integral¶
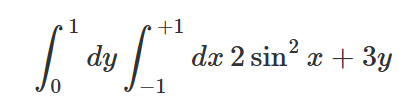
sympy.integrate( sympy.integrate( 2*sympy.sin(x)**2+3*y,( x,-1,+1 ) ),( y,0,1 ) )
不能用def的函数来替代
Taylor Series¶
sympy.series(f, x, x0, n[, dir='+'])
f: the function to expand
x: the variable
x0: the expansion point a (0 for Maclaurin series)
n: up to which order (n-1 terms will be shown)
dir: direction ('+' for right, '-' for left, default '+')
Linearization 保留泰勒展开的常数项和一次项¶
换句话说,求切线
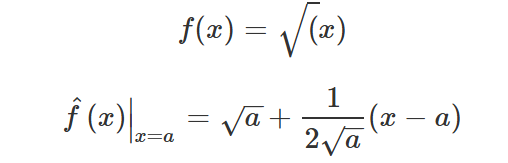
f = sympy.sqrt( x )
fhat = sympy.series( f,x,a,2 )
fhat = fhat.removeO() #是O不是0 !
>>> sqrt(a) + (-a + x)/(2*sqrt(a))
sympy.root(f,n) #f是函数,n是开几次根
expr是表达式
expr.sub(a,10) #表示a取10
sympy.lambdity([a,b],expr)
Lec21-Modul¶
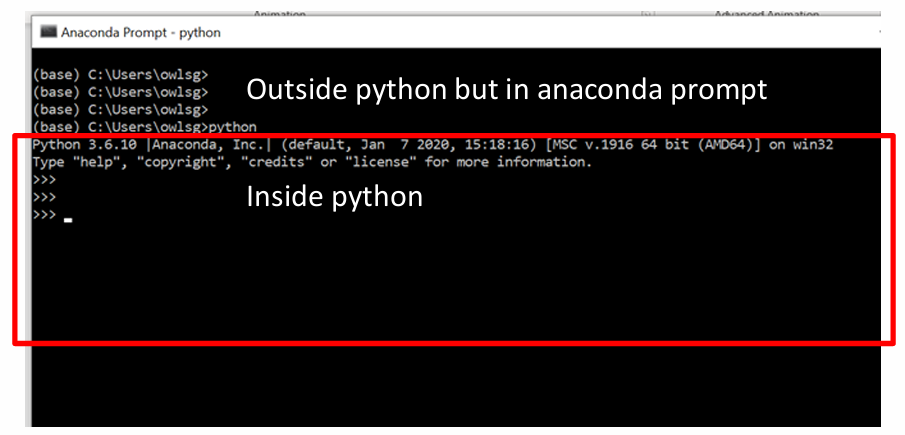
- 单个
>是外部,可以选择python的版本 >>>是特定python内部的环境
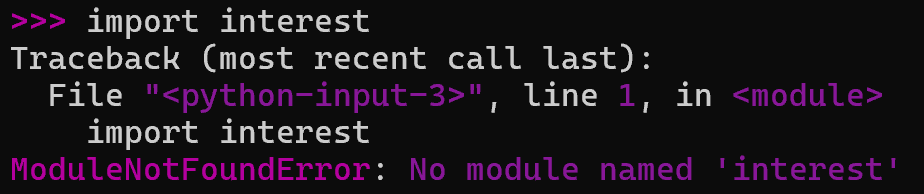
在外部环境输入:conda list --> 查看已有的库(pip list 也可)
下载¶
conda install XXX 在联网情况下,从服务器下载特定库 (pip install XXX 也可)
更新¶
conda upgrade XXX
pip install --upgrade XXX
chose [y]/n
删除¶
conda remove XXX
pip uninstall XXX
创建自己的库¶
在记事本里输入代码,然后把后缀改为 .py
代码里是这个库包含的(定义的)函数
记事本名称是库名称 interest.py 说明自己创建的库叫interest
创建库的位置¶
- Put your module file in the same folder as your own program (Easiest).
-
tell Python where to find our module
-
Place the module file in one of the folders in
sys.path
存在下面的路径中
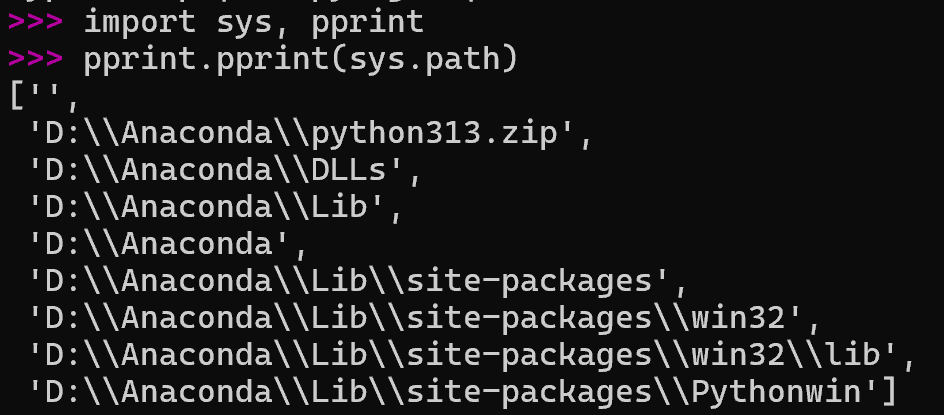
You are saving your module on your computer not on some internet computer!
更多的库¶
Pandas—Python for Data Analysisscikit-learnorPyTorch— machine learningClasses(object-oriented programming)Bokeh—interactive plots, like web graphics
Matlab¶
MATLAB 入门之旅摘要¶
基本语法¶
| 示例 | 说明 |
|---|---|
x = pi |
使用等号 (=) 创建变量。 左侧 ( x) 是变量的名称,其值为右侧 (pi) 的值。 |
y = sin(-5) |
您可以使用括号提供函数的输入。 |
桌面管理¶
| 函数 | 示例 | 说明 |
|---|---|---|
save |
save data.mat |
将当前工作区保存到 MAT 文件中。 |
load |
load data.mat |
将 MAT 文件中的变量加载到工作区。 |
clear |
clear |
清除工作区中的所有变量。 |
clc |
clc |
清除命令行窗口中的所有文本。 |
format |
format long |
更改数值输出的显示方式。 |
数组类型¶
| 示例 | 说明 |
|---|---|
4 |
标量 |
[3 5] |
行向量 |
[1;3] |
列向量 |
[3 4 5;6 7 8] |
矩阵 |
等间距向量¶
| 示例 | 说明 |
|---|---|
1:4 |
使用冒号 (:) 运算符,创建一个从 1 到 4,间距为 1 的向量。 |
1:0.5:4 |
创建一个从 1 到 4,间距为 0.5 的向量。 |
linspace(1,10,5) |
创建一个包含 5 个元素的向量。这些值从 1 到 10 均匀间隔。 |
创建矩阵¶
| 示例 | 说明 |
|---|---|
rand(2) |
创建一个 2 行 2 列的方阵。 |
zeros(2,3) |
创建一个 2 行 3 列的矩形矩阵。 |
索引¶
| 示例 | 说明 |
|---|---|
A(end,2) |
访问最后一行的第二列中的元素。 |
A(2,:) |
访问第二行所有元素。 |
A(1:3,:) |
访问前三行的所有列。 |
A(2) = 11 |
将数组中第二个元素的值更改为 11。 |
数组运算¶
| 示例 | 说明 |
|---|---|
[1 1; 1 1]*[2 2;2 2]ans = 4 4 4 4 |
执行矩阵乘法。 |
[1 1; 1 1].*[2 2;2 2]ans = 2 2 2 2 |
执行按元素乘法。 |
多个输出¶
| 示例 | 说明 |
|---|---|
[xrow,xcol] = size(x) |
将 x 中的行数和列数保存为两个不同变量。 |
[xMax,idx] = max(x) |
计算 x 的最大值及其对应的索引值。 |
文档¶
| 示例 | 说明 |
|---|---|
doc randi |
打开 randi 函数的文档页。 |
绘图¶
| 示例 | 说明 |
|---|---|
plot(x,y,"ro-","LineWidth",5) |
绘制一条红色 (r) 虚线 (--) 并使用圆圈 ( o) 标记,线宽很大。 |
hold on |
在现有绘图中新增一行。 |
hold off |
为下一个绘图线条创建一个新坐标区。 |
title("My Title") |
为绘图添加标签。 |
使用表¶
| 示例 | 说明 |
|---|---|
data.HeightYards | 从表data中提取变量HeightYards`。 |
|
data.HeightMeters = data.HeightYards*0.9144 |
从现有数据中派生一个表变量。 |
逻辑运算¶
| 示例 | 说明 |
|---|---|
[5 10 15] > 12 |
将向量与值 12 进行比较。 |
v1(v1 > 6) |
提取 v1 中大于 6 的所有元素。 |
x(x==999) = 1 |
用值 1 替换 x 中等于 999 的所有值。 |
编程¶
| 示例 | 说明 |
|---|---|
| if x > 0.5 y = 3 else y = 4 end |
如果 x 大于 0.5,则将 y 的值设置为 3。 否则,将 y 的值设置为 4。 |
| for c = 1:3 disp(c) end |
循环计数器 (c) 遍历 值 1:3(1、2 和 3)。 循环体显示 c 的每个值。 |