Hua Chen - Embodied AI & Humanoids Robots
General Introduction to Robotics and Embodied AI¶
Classification¶
- Aerial (空中): DJI,仿生扑翼机
- Underwater(水下):水下探测器,仿生机器鱼
- Legged(足式/腿式):目前最前沿火热的领域
- 四足(机器狗,如宇树、波士顿动力Spot)
- 双足/人形(Humanoid Robots,宇树、波士顿动力Spot)
- 为什么要研究足式和人形? 因为人类社会是为两条腿和两只手设计的,只有人形机器人才能完美适应人类的生活和工业环境
Motivation¶
- Bio-mimicry(仿生学)
Traditional Robotics Architecture¶
- Cognition(认知大脑)
- LLM:大语言模型,被用来作为高级的策略生成器,赋予了机器人常识和逻辑推理能力。
- VLM(Vision-Language Model - 视觉语言模型):LLM的升级版,不仅听懂文字,还能看懂图片。在具身智能中,VLM 通常被用作大脑的Backbone。比如你指着桌子说“把那个红色的苹果递给我”,VLM 能够处理你的语音指令,并在摄像头画面中精准识别出哪个是红苹果。
- HRI (Human-Robot Interaction - 人机交互)
- Planning(规划导航)
- SLAM (Simultaneous Localization And Mapping - 同步定位与建图):Mapping(建地图)+Localization(定位)
- Navigation:SLAM建立好地图后,规划从出发点到终点不会撞到障碍物的最优路线
- Control(小脑控制层)这一层负责指挥机器人身上几十个电机的具体运动,让它走得稳、抓得准
- MPC (Model Predictive Control - 模型预测控制):这属于经典的基于物理模型的控制方法(Model-based Control)。机器人会利用极其复杂的物理动力学公式,去预测未来几秒钟内的行为和受力情况,然后通过求解数学上的“最优化问题”,算出当下每个关节电机应该输出多大的力矩
- Reinforcement learning(RL - 强化学习):目前极火的数据驱动(Data-driven) 方法:抛弃复杂的物理公式推导,利用神经网络(Neural Network) 海量数据来做近似。 与 MPC 写物理公式不同,强化学习不教机器人具体的物理公式,而是把它扔进仿真环境里让它自己试错(Trial-and-error)。做得好就给奖励(Reward),摔倒了就惩罚(Penalty)。经过成千上万次的迭代,神经网络自己就学会了后空翻或者抗踹不倒的技能。
- Hardware Platform(硬件平台)
- Actuators(执行器 / 驱动器 - 机器人的“肌肉”):分为电机驱动(主流)、液压驱动(力量大)有的机械臂可能不是最好的选择,现在的难点在于怎么造出一条又轻又高动态(爆发力强)的胳膊
- Mechatronic systems(机电一体化系统 - 机器人的“骨骼与神经”):不仅包含机器人的钢铁骨架、齿轮、连杆(骨骼),还包含把大脑指令传递给肌肉的电路板、单片机、线缆(神经系统)
- 机械设计(Mechanical Design):用 SolidWorks 等软件画出机器人的3D结构,考虑重力、应力
- 嵌入式系统(Embedded):比如 51单片机、STM32芯片。它们安装在机器人的关节附近,负责接收电脑传来的信号,并直接控制电机转动
当前现状
- 传统的“纯机械结构设计”已经很成熟,“很难玩出花来了”。未来硬件系统的两大基石是“新材料”和“新驱动”。如果能用更轻、更具弹性的新材料来做机电系统,机器人的运动性能就会发生质的飞跃。
- 现在的具身智能前沿,硬件正在变得越来越“标准化”,而核心的壁垒转移到了“算法(VLA与WBC)”上。就像大家都在买同一款宇树机器狗,比的是谁写的算法能让它跑得更稳
Legged and Humanoid Robots¶
History¶
- 硬件驱动的演进:早期依赖液压/气压驱动(Hydraulic/Gas)(力量大但笨重)--> 现代转向纯电机驱动(Electrical actuation)--> 未来探索新材料与新形态(New Morphologies)。
- 控制算法的演进:传统控制(Classic Control)--> 基于物理模型的预测控制(MPC)--> 数据驱动的机器学习(Learning)
Features¶
- Multiple Limbs 多肢体
- Discrete contact 离散接触:对环境的接触是断断续续的(足式机器人走路时,脚步是“抬起-悬空-落下-踩实”,它与地面的接触点在不断变化,也就是“离散”的)
- 难点:每次脚悬空的时候,机器人都在“摔倒的边缘”。所以研究的重心之一,就是怎么用 MPC或者RL算出极其精准的落脚点和发力大小,保证它在“断续接触”中始终保持动态平衡(比如推它一把它还能找回平衡)。
- 🏃Locomotion: Change own pose/status 主要归 WBC(小脑)管
强化学习(RL)在四足机器人上的应用,主要都是为了解决 Locomotion 走得稳、跑得快的问题 - 🖐️Manipulation: Change target object’s pose/status 主要归 VLA视觉语言动作模型(大脑)管
用视觉(相机)看懂环境,用语言理解指令,然后精准控制末端的手爪去操作物体 - ...
Problem(目前全球科研难题):Loco-Manipulation(移动操作)¶
Change own pose/status as well as target object’s pose/status
Eg: 机器人需要一边走一边干活。比如它在搬运一个很重的箱子,大脑(VLA) 要控制手臂抱紧箱子(Manipulation),小脑(WBC) 要为了对抗箱子的重力,迅速调整腿部的发力姿势保持不摔倒(Locomotion)
Modern Embodied AI Architecture (End2End)¶
Embodied AI¶
具身智能(Embodied AI)是指所有能通过物理身体与真实环境交互的AI系统;而在最前沿的足式/人形机器人赛道中,具身智能的核心使命,就是把底层的Locomotion(走得稳)和高层的Manipulation(干得准)融合,实现极高难度的 Loco-Manipulation
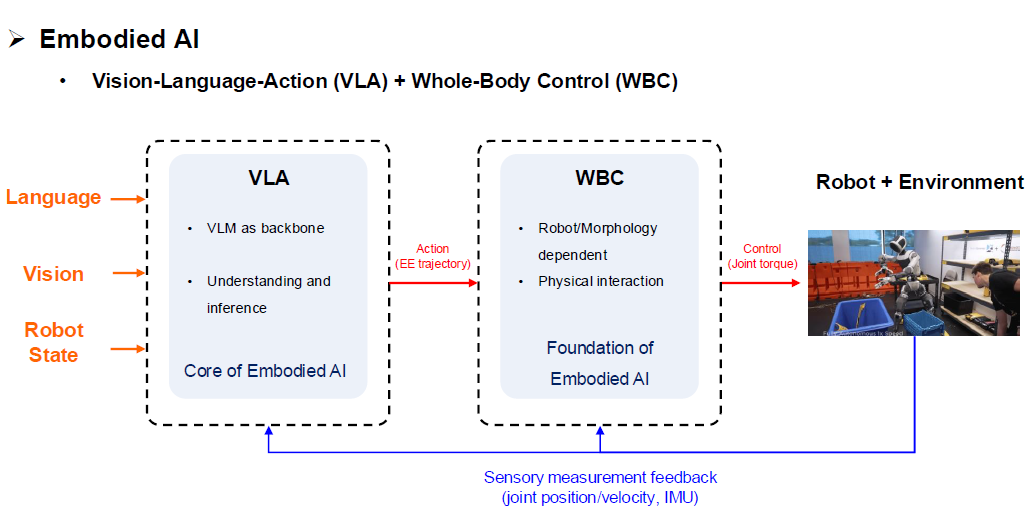
- 过去,机器人界采用的是界限分明的传统架构:
先看懂(Cognition),再想好路线(Planning),最后控制电机执行(Control)。 - 但在现代具身智能 时代,端到端大模型的出现打破了这堵墙,形成了‘大脑+小脑’的全新架构:
具身智能 = VLA(大脑) + WBC(小脑)
🧠VLA (Core of Embodied AI)¶
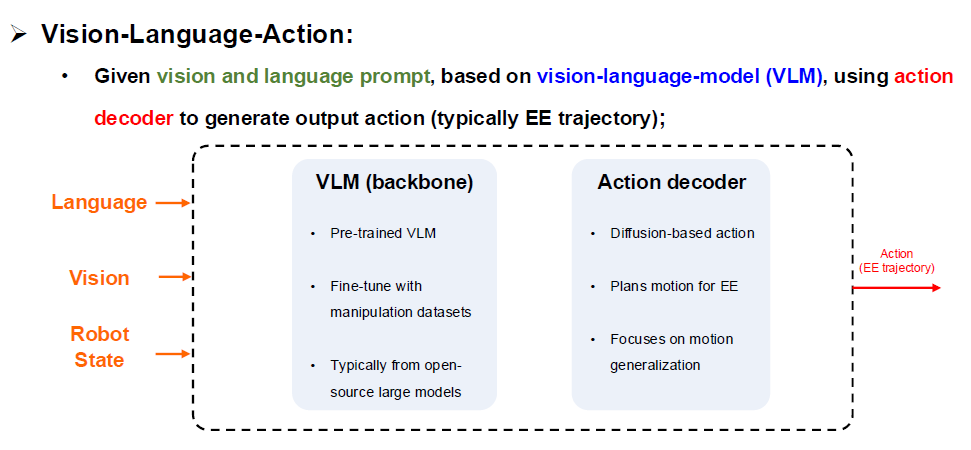
传统的 VLM 只负责认知,规划和控制要交给其他算法去做
VLA是能直接指挥机器人行动的端到端(End2End)大脑,包含了VLM
VLA (Vision-Language-Action,视觉-语言-动作模型),通过神经网络直接从认知跨越到动作输出
- 它是将 VLM 与机器人控制 结合起来的模型。
- 它的工作原理是:
- 大脑的输入(听与看):
- Vision(视觉):机器人头上的摄像头拍到了前方的桌子和杯子。
- Language(语言):你下达的语音指令“拿杯子”。
- Robot State(机器人状态):机器人现在的手在什么位置。
- 大脑的处理中枢:VLM (Vision-Language Model,视觉语言大模型)
- 这是整个VLA的骨干(Backbone)。你可以把它理解为长了眼睛的ChatGPT。它能将你说的“拿杯子”和摄像头画面结合起来,在脑海里定位:“哦,杯子在画面的左上角,主人要我去拿它。”
- 这部分通常是利用开源的预训练大模型(open-source pre-trained LLM),然后用专门的机器人抓取数据去微调(Fine-tune) 它。
- 大脑输出层的两大流派:
- 走扩散模型(Diffusion Model):外接一个Action Decoder(动作解码器),直接利用复杂的神经网络生成连续的三维物理轨迹矩阵(EE trajectory),然后丢给小脑
- 走自回归大模型(Autoregressive Models):Action Tokenization(动作Token化),Tokenizer(动作分词器 / 编码字典) 通过把物理世界离散化,给每个坐标 编上号如
[Action_001]这样的token。VLM思考后输出的一串token会通过Detokenizer(反分词器 / 动作解码翻译器) 类似查字典来翻译回三维物理轨迹矩阵。
🦴WBC (foundation of Embodied AI)¶
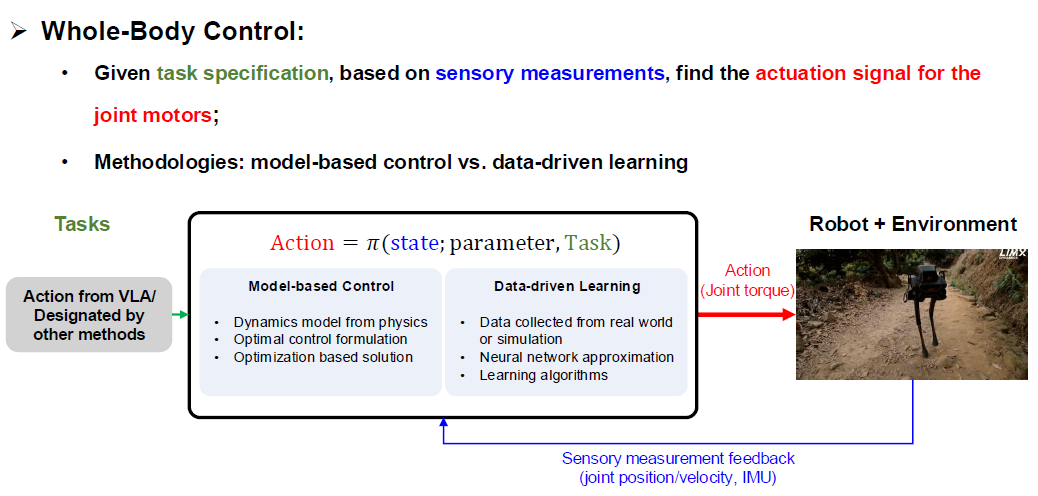
WBC 是机器人的小脑(Foundation of Embodied AI,基础层),让全身几十个电机协调发力、保证机器人不摔倒
- 小脑的输入:
- 小脑接到了大脑(VLA)传来的精确的 3D物理轨迹矩阵
- 接收着机器人身上的传感器数据(Sensory measurement feedback,比如当前各个关节的角度、陀螺仪 IMU 传来的身体倾斜度)
- 小脑的输出:Joint torque(关节力矩)
- 小脑结合输入的数据疯狂进行计算,输出机器人全身每一个电机的极其精准的电流/扭矩指令。比如:“左腿膝盖电机输出5牛米的力支撑身体,右肩电机输出2牛米的力抬起胳膊”。
-
- 流派一:Model-based Control(基于物理模型的控制)
基于物理学的动力学公式(Dynamics model from physics)。通过求解最优控制数学方程,算出怎么发力最稳。其中的代表技术是MPC(模型预测控制),MPC 拿着 Model-based Control 写好的物理公式,在每一个极其微小的时间周期内,去“预测”未来几秒钟机器人的受力情况,然后通过求解一个最优化数学题,算出当下这一刻每个电机应该出多大力(优化性能指标的同时满足物理约束)。这需要极强的微积分和动力学基础。
小脑的两大控制方法:WBC的两大流派
- 流派二:Data-driven Learning(数据驱动的机器学习)
不写复杂的物理公式了,用神经网络(Neural Network) 去做近似。把机器狗扔进仿真环境里,通过“试错”来学习怎么保持平衡。其中目前最火的 RL(强化学习) 技术和 IL(Imitation Learning 模仿学习)。
- 流派一:Model-based Control(基于物理模型的控制)
Recent Advances in VLA¶
- Hierarchical VLM-VLA(分层视觉语言动作模型)
- Figure.ai公司: Helix系统(慢思考中枢/理智脑+快反应中枢/本能脑)
- 难题:VLM过于庞大,算的太慢。大模型要理解“去把左边的黄油拿给机器人”这句话,可能需要思考 0.1 秒;但在物理世界里,机器人如果 0.1 秒不调整电机的力量,手里的黄油可能就掉地上了。
- 慢思考中枢/理智脑:一个参数量高达 7B(70亿)的预训练 VLM 大模型。负责低频的“视觉-语言语义推理”。它听懂你的指令,看懂画面,思考“我要去抓黄油”。它不直接控制电机,而是输出一个浓缩了意图的 Latent Vector(潜在特征向量/意图信号),传给本能脑。
- 快反应中枢/本能脑:一个仅有 80M(8000万)参数的小型 Transformer 模型。因为小,所以跑得飞快。负责快速的反应控制。它接收“慢脑”传来的意图,结合机器人当前极高频的身体状态(关节角度、手指位置),瞬间输出机器人的控制指令。
- VLM+Action Decoder
- Physical Intelligence: \(\pi_0\) / \(\pi_{0.5}\) 模型(一个能控制全天下所有机器人的通用基础大脑)
- 极其庞大的输入(Multimodal Data / 多模态数据):- 不仅吃传统的“机器人操作数据”(Robot Action Data,比如在实验室叠衣服、在真实家庭里铺床),它还吃海量的互联网多模态数据(Multimodal Web Data)。这意味着,它在网上看了无数人类的视频和图片,虽然它还没长手,但它已经在赛博空间里学会了“杯子是什么”、“衣服该怎么叠”这种人类世界的物理常识。
- 统一的动作解码器(Action Expert):基于扩散模型(Diffusion Model) 的动作生成。
- DYNA(特定场景的端到端应用)
Recent Advances in WBC¶
General Control Architecture for Control of Legged Robots¶
- Model-based Optimal Control(基于物理模型的经典控制)
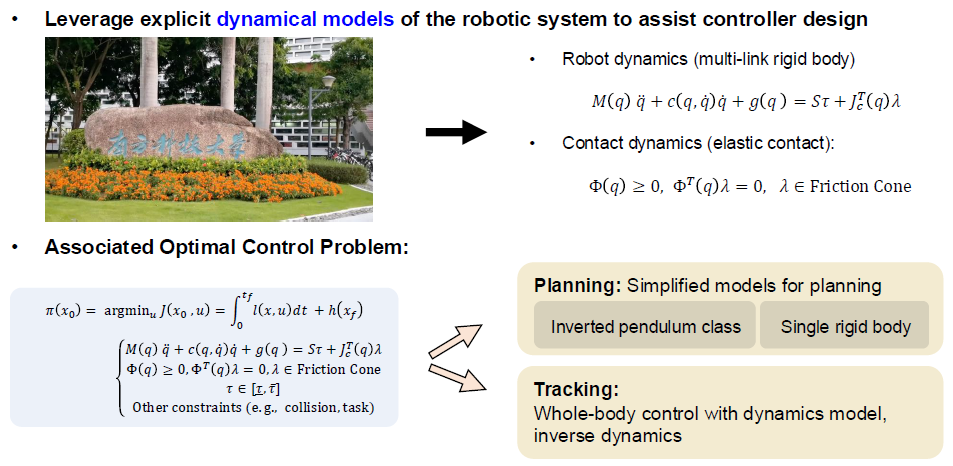
图中的Robot dynamics(multi-link rigid body)公式,其实就是牛顿第二定律在多关节机器人上的终极复杂版,计算了机器人的质量惯性、重力、摩擦力以及地面的接触力
极其精准,具有严格的物理边界;但当环境太复杂(比如泥地、被人猛踹一脚),物理公式算不过来时,机器人就容易崩溃。
- Data-driven Reinforcement learning
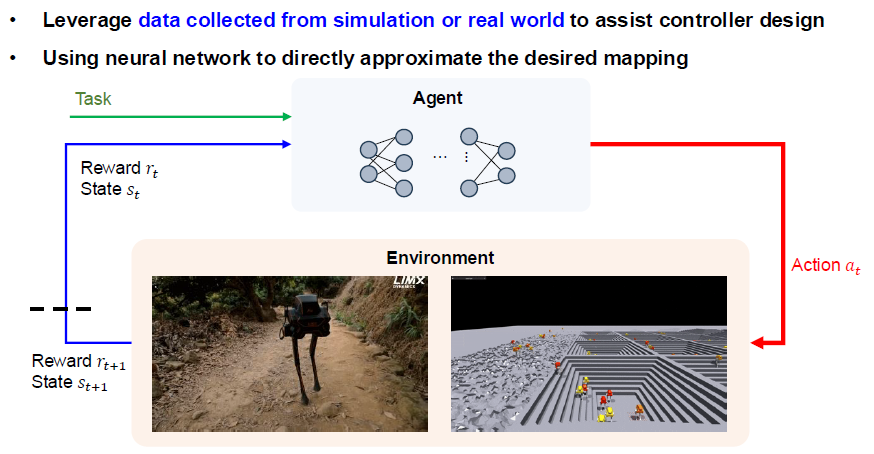
Agent(智能体)与 Environment(环境)交互,通过 State(状态)、Reward(奖励)和 Action(动作)不断循环
既然Learning这么强,MPC是不是被淘汰了,它对Learning还有什么意义?
MPC 是 Learning 的天花板和引路人
- 为 Learning 提供安全与物理边界(约束):纯靠 RL 学习的机器人,动作往往狂野且不符合物理常理,直接放到真机上容易烧毁电机(Sim-to-Real Gap)。MPC 中的各种动力学约束,经常被用来指导 RL 的训练,甚至有专门的前沿方向叫 基于学习的MPC(Learning-Based MPC),将两者的优势结合
- Reward(奖励函数)的设计极度依赖 MPC 的物理直觉:在强化学习中,你怎么告诉神经网络什么是“好”的走路姿势?这就需要你对“能量消耗最优”、“接触力(Contact force)最小”、“关节力矩(Joint torque)最平滑”有极深的理解,而这些概念全都是在 MPC 和机器人动力学中培养出来的物理直觉。
Model-based and Data-driven Learning for Legged Control¶
- Quadruped locomotion – robustness enhancement(四足机器狗:增强的鲁棒性)
- Robustness(鲁棒性/抗造性):在真实世界里,机器人不可能永远走在平坦的水泥地上,它会遇到未知的高低差、外力撞击
- Reachability-guided push recovery control (2022):基于模型(Model-based)的MPC控制。当被人踹一脚时,小脑瞬间用物理公式算出“我的脚还能踩到哪块区域(可达性区)才能不摔倒”,然后迅速迈出那一步。
- Concurrent teacher-student reinforcement learning (2024):数据驱动的强化学习框架。在虚拟仿真里训练一个拥有上帝视角的“老师网络”,再把它学到的平衡本领传授给只能靠自身传感器感知的真机“学生网络”。经历几百万次试错后,机器狗练就了肌肉记忆,闭着眼睛踩空台阶也能瞬间稳住。
- Bipedal locomotion – from possible to unbeatable(双足机器人的进化)
- Perceptive Locomotion(感知移动):给底层物理控制加了一个“短距地形雷达”(结合视觉深度摄像头),让底层控制算法能看到前方的台阶,从而提前调整腿部的发力。这就是感知(Perceptive)与底盘移动(Locomotion)的融合。
- 与 VLA 大脑用来理解语义的彩色视觉(RGB) 不同,小脑的感知雷达通常使用的是深度图或点云(几何视觉),它不关心石头长什么样,只计算石头有多高,从而实现提前预判的发力。
- Loco-manipulation – the interface to Embodied AI(具身智能的终极接口)见上文
- Human Motion Imitation & Large Behavior Model(大行为模型,LBM)
- VLA方向有\(\pi_0\) 基础大模型,投喂海量的互联网人类视频-->WBC方向有LBM大行为模型。把人类穿戴动作捕捉服(Mocap)打太极、跳舞、后空翻的海量动态数据喂给小脑。强化学习不再仅仅是为了“不摔倒”,而是让机器人拥有像人类一样流畅、极其复杂的爆发力和协调性。
Robot Learning, Machine Learning, Reinforcement Learning & Imitation Learning的关系
- 机器学习(ML) 是底层的算法土壤,深度学习(DL) 是其最高级的神经网络工具。
- 按照学习方式,机器学习分为 监督学习(给答案)、无监督学习(不给答案)、强化学习(RL,给奖惩分数)。
- 当这些算法被专门用来让机器人动起来时,这个交叉学科领域就叫 机器人学习(Robot Learning)。
- 在机器人学习中,目前最火的两大绝招就是:让机器人自己试错的 强化学习(RL),以及让人类直接演示给它看的 模仿学习(IL)。
写在最后¶
本篇笔记是笔者基于Hua Chen教授的Embodied AI and Robotics导论课与课题组学长推荐资源进行学习,总结整合的博客笔记,开源和大家交流。全文在一些概念解释和逻辑架构方面不够深入浅出。毕竟本文的初衷是为了实现对具身智能粗略框架的介绍,便于自己和各位初步了解以及为将来走入Embodied AI作一个底层架构的支持。
因此,关于该笔记的任何疑问和建议,笔者都强烈欢迎甚至是呼吁。请点击右下角的联系方式。Contact with me through email or my WeChat official account.
但是具身智能发展极快,各种框架眼花缭乱。作为初学者,不要盲目去追每一个细分领域的 Paper,而是先建立宏观的骨架认知(比如这篇博客总结的框架),在大一大二踏踏实实学好微积分、物理和TAM,剩下的交给科研”试错”就好。